1. 기초통계량 :
데이터를 요약해서 이해하기 쉽게 보여주는 숫자.
1) 평균(average) : 모든 데이터를 더하고 데이터 개수로 나눈 수, 데이터 전체를 한눈에 보여주는 대표값, 엄청 크거나 작은수가 있으면 평균이 왜곡될 수 있음.
2) 중앙값(median) : 데이터를 크기순으로 정렬했을 때 가운데 있는 수, 데이터 개수가 짝수면 가운데 두 수의 평균을 구함, 극단적인 수의 영향을 덜 받음.
3) 최빈값(mode) : 숫자들 중 제일 자주 나온 수, 모든 수가 동일하게 나오면 최빈값 없음,
4) 범위(range) : 숫자들 중 제일 큰 값에서 제일 작은 값을 뺀 수.
# 중심 경향도 : 데이터의 대표값을 찾아서 복잡한 수자 더미를 간단하게 이해하도록 해줌.
2. 평균의 종류
1) 산술평균(arithmetic mean) : 숫자들을 다 더해서 숫자의 개수로 나누는 방법, 전체적인 크기를 고르게 반영할 때 좋음.
2) 기하평균(geometric mean) : 숫자들을 곱한 뒤 그 곱의 n번쨰 루트를 구하는 방법, 곱셈 관련 상황에서 사용(주식수익률, 인구 증가율 등)
3) 조화평균(harmonic mean) : 숫자들의 역수를 더하고, 그 합을 숫자 개수로 나누고, 다시 역수로 바꾸는 방법, 속도, 효율, 비율처럼 단위당 계산이 중요한 경우 유용.
4) 절사평균(trimmed mean) : 데이터 양 끝의 극단적인 값을 제거하고 남은 수의 산술평균을 구하는 방법. 이상치의 평균 왜곡을 막는 방법.
3. 산포도 :
중심에서 얼마나 떨어져 있는지를 측정. 데이터가 평균 근처에 몰려있으면 산포도가 작고, 멀리 퍼져있으면 산포도가 큼.
4. 변동계수 :
데이터의 퍼짐정도(산포도)를 데이터의 평균으로 나눠서 백분율로 나타낸 것. 평균에 비해 얼마나 흩어져 있는지 퍼센트로 보여줌. 데이터의 단위가 달라도 퍼짐정도를 공정하게 비교하도록 해줌.
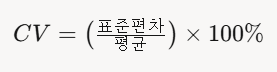
5. 사분위수 :
4개의 같은크기 그룹으로 나누는 값들. 데이터를 작은것부터 큰 것까지 정령하고, 20%, 50%, 75%, 100%지점에서 나눔. 데이터의 퍼짐정도를 보여주고, 이상치에 덜 민감하여 데이터의 가운데 부분을 분석할 때 유용. 데이터의 분포를 이해하거나 이상치를 찾을 때 유용.
6. 비대칭도 :
1) 왜도 : 데이터 분포의 모양이 치우친 정도의 수. 분포의 모양을 이해할 수 있음.
(1) 왜도 = 0(대칭분포) : 데이터가 평균을 중심으로 대칭
(2) 왜도 > 0(오른쪽으로 치우친 분포, 양의 왜도) : 데이터가 오른쪽으로 긴 꼬리를 가짐
(3) 왜도 < 0(왼쪽으로 치우친 분포, 음의 왜도) : 데이터가 왼쪽으로 긴 꼬리를 가짐
(4) 수식 : 각 데이터가 평균에서 얼마나 떨어져 있는지를 세제곱한 뒤, 평균을 내고 표준편차로 나눠서 구함.

2) 첨도 : 데이터의 분포 모양이 얼마나 극단적인지, 가운데가 뾰족하거나 납작한지를 측정.
(1) 중첨도 : 데이터 분포가 정규분포와 비슷함.
(2) 고첨도(첨도 > 0) : 분포가 정규분포보다 더 뾰족하고 꼬리가 두꺼움. 데이터가 평균 근처에 많이 몰려있는 경우.
(3) 저첨도(첨도 < 0) : 분포가 정규분포보다 더 납작하고 꼬리가 얇음. 평균근처에 덜 몰리고, 극단적인 값이 적음.
(4) 수식 : 데이터가 평균에서 얼마나 떨어져 있는지를 네제곱한 뒤, 평균을 내고 표준편차로 나누서 구함.

'Study > 통계학을 공부해보자' 카테고리의 다른 글
| 2-2 데이터의 표현 방법 (0) | 2025.04.15 |
|---|---|
| 2-1 데이터의 수집 (0) | 2025.04.11 |
| 1-3 표본분포와 중심극한정리 (0) | 2025.04.09 |
| 1-2. 표본의 분포 (0) | 2025.04.07 |
| 1-1. 모집단과 표본추출 (0) | 2025.04.03 |







